When doing inference with Llama 3 Instruct on Text Generation Web UI, up front you can get pretty decent inference speeds on a the M1 Mac Ultra, even with a full Q8_0 quant.
Early on I’m getting around 4-5 tokens per second which is good for a 70B Q8 of a GGUF. However, as the chat context size pushes towards the 8k max the speeds start to slow down quite a bit.
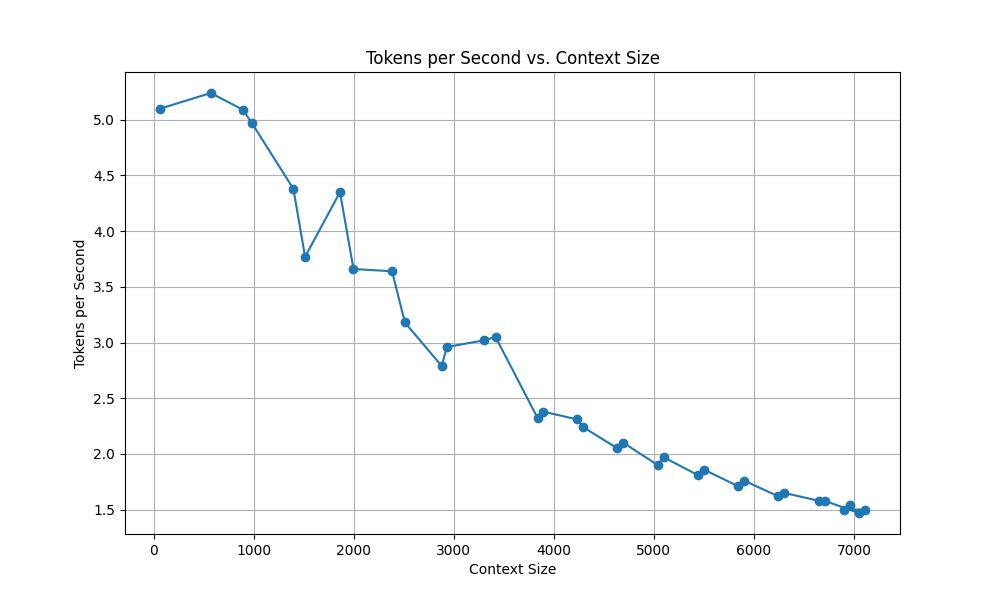
At issue is that as the context grows the chat history gets added to the prompt, which increases the amount of processing on the prompt itself by quite a bit.
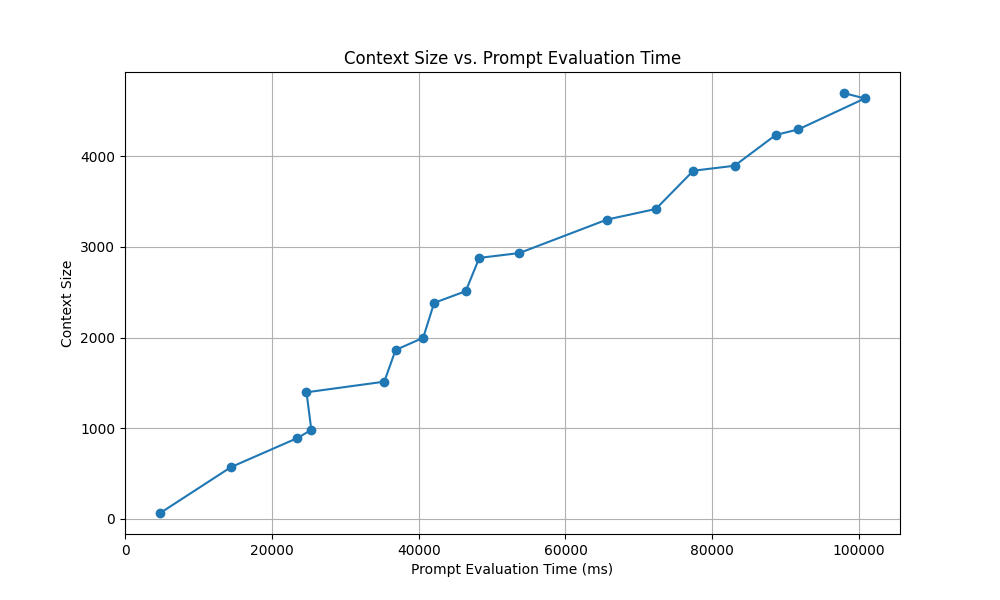
So while the streaming response itself stays at the same speed, there’s a long pause in between generations as the large prompt(current chat + entire chat history) has to get processed. This makes for a pretty miserable chat experience.
Prompt Caching
Fortunately even though the model itself takes 70 gigs of RAM, being on a 128GB Mac gives us a lot of extra RAM we can use to cache the tokens of the prior prompts and bypass this process.
In order to access this mode, we need to start the app with cache enabled:
./start_macos.sh --listen --api --cache-capacity 8GiB --streaming-llmThis gives is 8 gigs of RAM set aside for caching the prompt. This dramatically changes the tokens per second we get at high context usage:
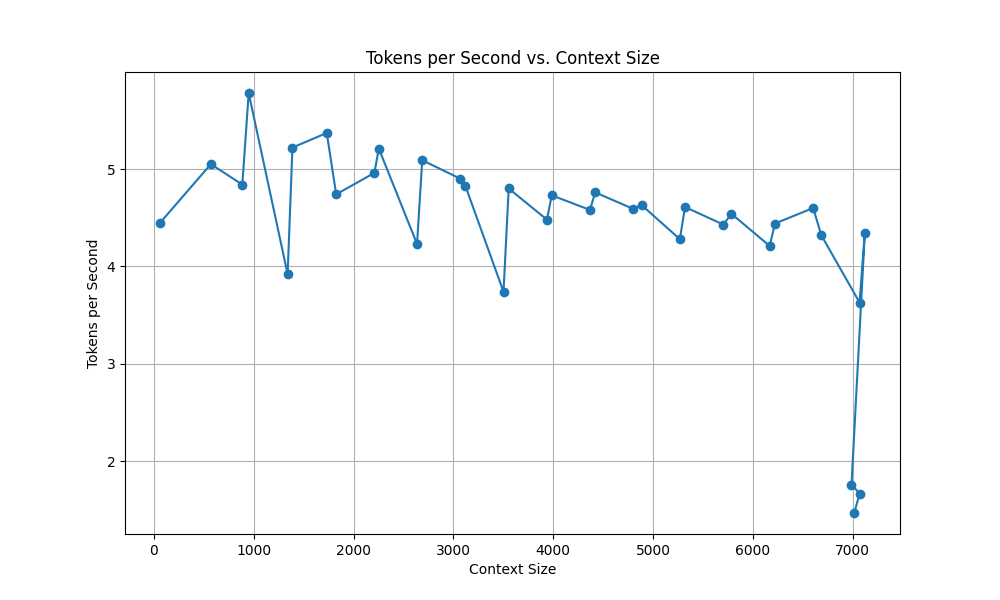
And here we can see that the prompt generation is pretty static as it hits on the prior cache, even though our prompt is growing in size to max out the context.
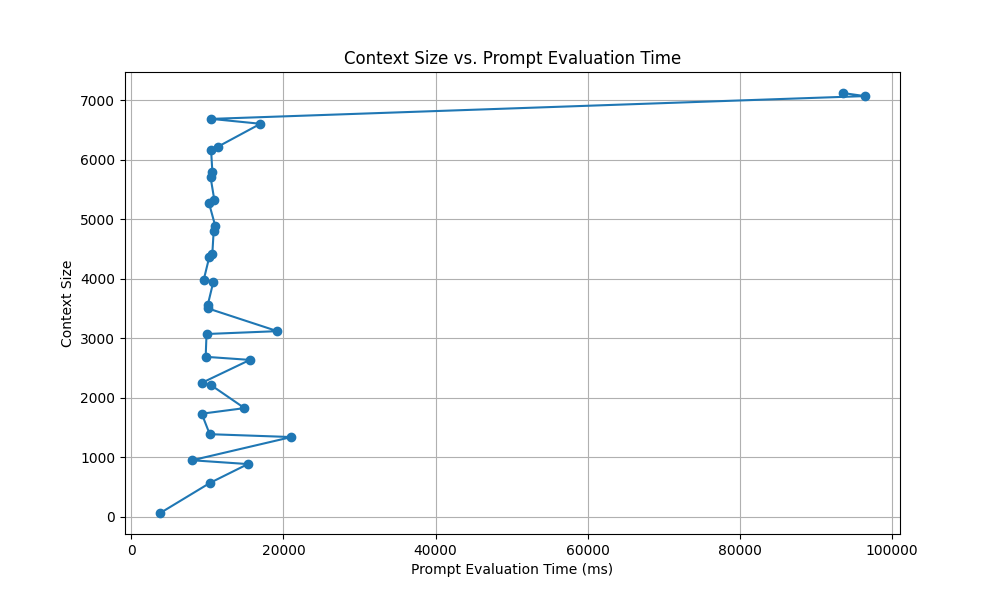
This creates a much more pleasant chat experience even at near max context.
I ended the chat at about the time the context maxed out, which would force prior context to start to drop out of chat history. That may be the cause of the final drop in tokens per second and high prompt processing on the final requests. I’m unsure if Text Gen handles chopping out cached context gracefully or if there’s a high overhead on that. KoboldCPP may handle this better or there may be other ways to tune this process in Text Gen.