In this post I’ll be walking through setting up Text Generation Web UI for inference on GGUF models using llama.cpp for Mac. Future posts will go deeper into optimizing Text Gen for faster prompt digestion during chatting with bots. The eventual goal is to try to get as close as possible to Nvidia speeds with long context(16k+) chats.
Installing Text Gen
We will not be using Conda directly during this install and rather relying on the internal install scripts to setup the Conda environment for us.
cd ~/src
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui/
./start_mac.sh --listen --api
Once the install finishes, you can go to http://your-mac-ip:7860 for the web interface.
Enabling Prompt Caching
Macs are pretty slow when it comes to tokenizing the prior prompt history, but we have a lot of RAM which we can use the cache those tokens for a speedup on future prompts. To use this start the app with the below command:
./start_macos.sh --listen --api --cache-capacity 8GiB --streaming-llmIn general, you may want 2GiB of cache per 4k of context you want to cache.
Speed – No Caching
In this use case, we’ll run Text Gen without any caching.
./start_macos.sh --listen --apiHere’s a chart of tokens per second vs context size(prior chat history) for 1 hour of two chat bots talking with each other without caching enabled.
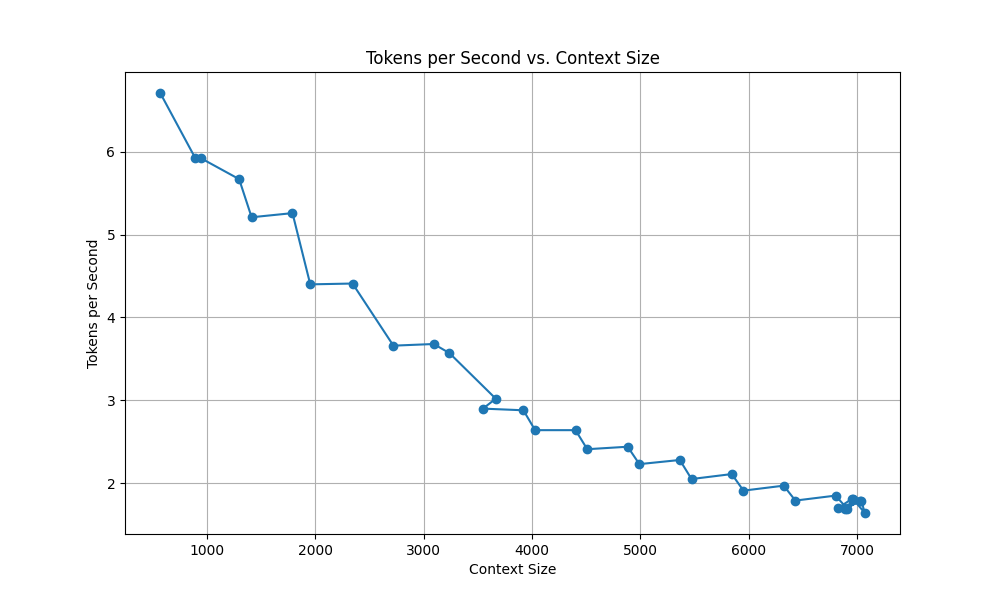
As you can see, the tokens per second drop dramatically as the context length(prior chat) has to be processed.
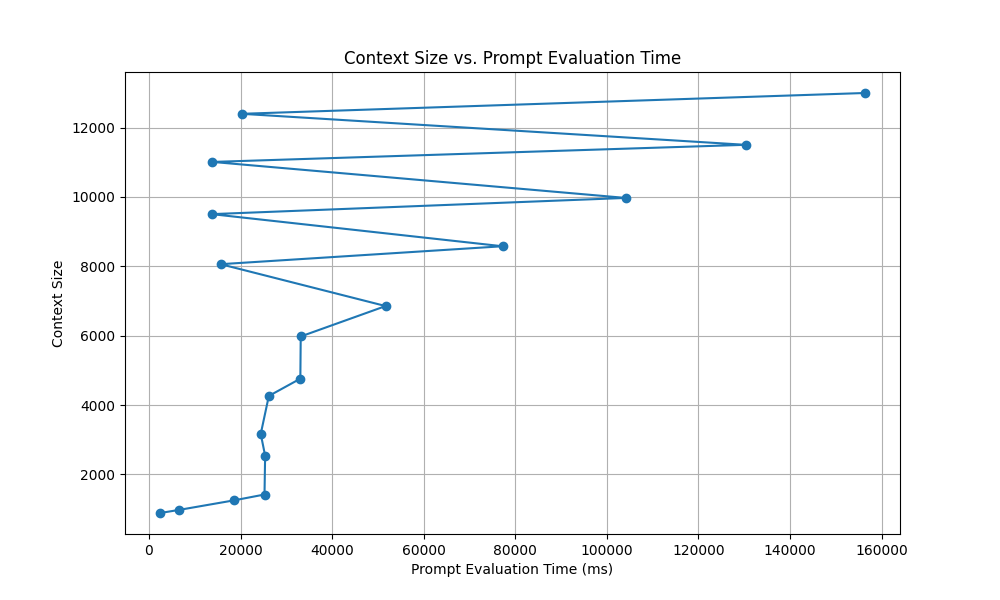
As the context grows, prompt speed(processing all the prior context) drops off a cliff even though we only reach 8k context.
Speed – Caching
With the caching enabled:
./start_macos.sh --listen --api --cache-capacity 8GiB --streaming-llmWe have a much better experience when our context maxes out at 16k after an hour of bots chatting with each other.
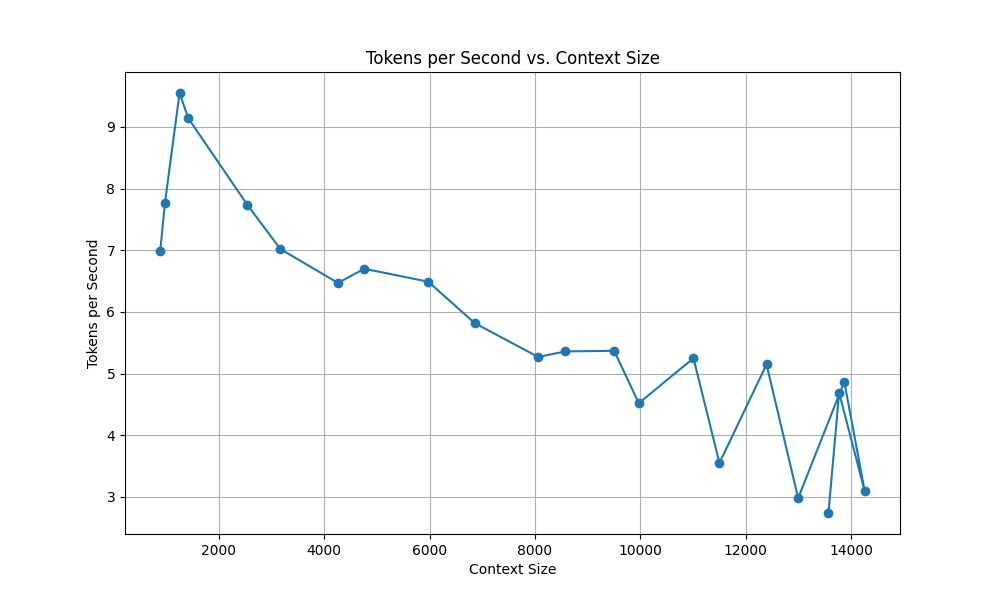
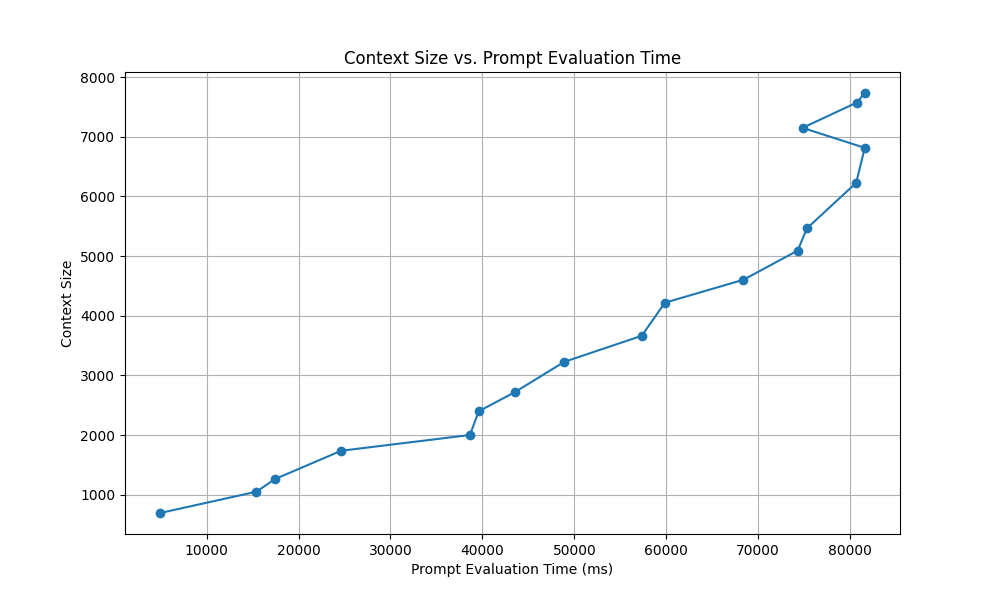
We can see this impact with the prompt speed processing, as we get cache hits(fast prompt speed) in the upper context lengths, even beyond 12k context being used.